Unsupervised anomaly detection automates equipment and infrastructure maintenance tasks previously performed by experts.
Among its features, the BLPredict equipment management platform offers the possibility of manually defining alert thresholds to be warned when monitored systems break down. To do this, each case of failure must be referenced using specific criteria traceable in the measurements taken by the sensors.
However, it’s difficult to know the full list of possible failures. More often than not, we have to wait until we observe them (and therefore suffer the consequences) to formalize them… which can prove costly. Unsupervised anomaly detection could alleviate this problem by automatically identifying unexpected behavior and informing the operator directly.

But what is anomaly detection?
The aim of anomaly detection is to highlight suspicious behavior or degraded operation by analyzing system data. It seeks to detect symptoms, and thus differs from diagnosis, which identifies causes.
Anomaly detection is divided into two categories:
- Supervised detection involves learning from labeled data, i.e. measurements with the label “normal” or “abnormal”. This detection approach generates a model that separates normal from abnormal measurements. Sometimes, it can even suggest an initial diagnosis.
- Unsupervised detection involves learning from unlabeled data, i.e. a set of measurements whose state is unknown. This detection method creates a model that formulates hypotheses to establish patterns of normality within the data.
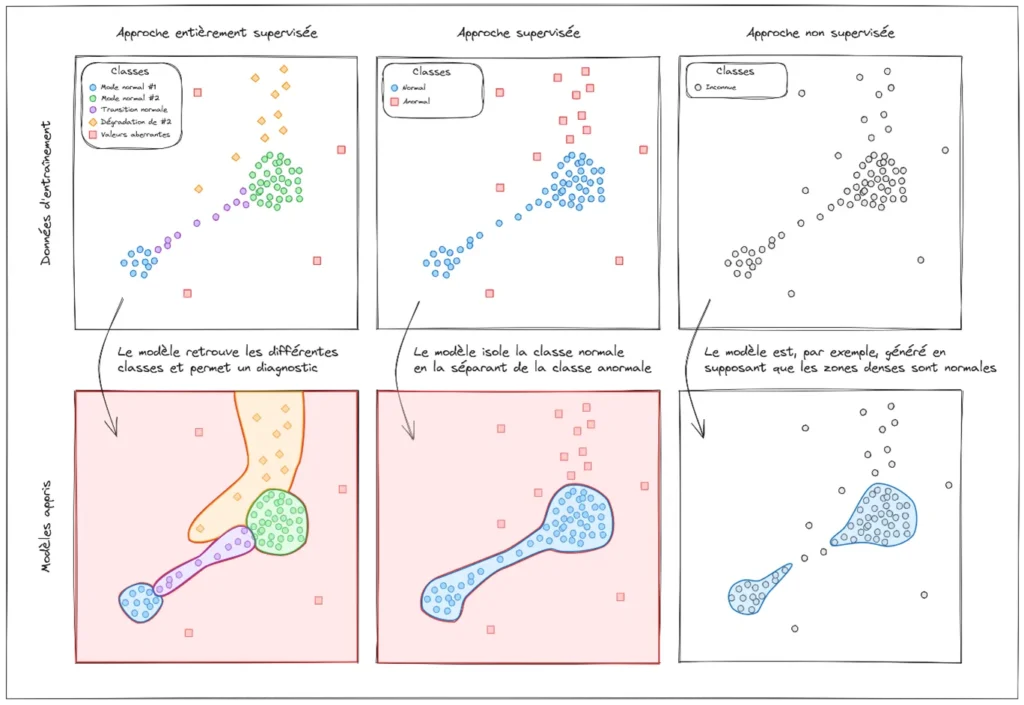
In practice, unsupervised methods characterize abnormality by means of an anomaly score; the higher the score, the more likely the data analyzed is to characterize a potential failure.
What's special about BLPredict?
With BLPredict, sensors are positioned on equipment to monitor and understand its operation. These sensors collect data streams; time-stamped measurements in real time. These measurements need to be processed on an ongoing basis, as abnormal behavior needs to be detected as early as possible.
The systems studied also have the particularity of evolving over time, following distinct operating modes or receiving a command to modify their behavior. Anomaly detection models must therefore be able to adapt to these changes, which is not the case with static methods, which are still commonly used.
Our answer with BLPredict
To integrate with BLPredict, anomaly detection methods must meet the following requirements:
- Adapt quickly to new measures,
- Be light in memory (with independence from the number of measurements), fast to run and easy to interpret, to facilitate diagnosis downstream from detection,
- Be easy to set up to reduce the degree of human supervision required for deployment and operation,
- Propose understandable performance metrics,
- Offer the possibility of combining several models into one to pool knowledge on similar systems.
Limits of current approaches
The approaches currently in place take two forms:
- The definition of threshold-based alerts for personalized monitoring of a system’s correct operation: this can quickly become inflexible when the thresholds to be set are non-linear, dependent on a large number of attributes (multiplication of clauses) or when there is a large number of abnormal behaviors (multiplication of rules).
- The use of a static anomaly detection method called One-Class SVM to ensure the stability of a system’s behavior: static by nature, it doesn’t allow us to follow the evolution of behavior, which is necessary to detect any change and start a new learning process adapted to the new behaviors of the equipment to be managed.
Technical aspects and benefits of our solution
In order to optimize equipment and infrastructure management, several methods can be used to detect anomalies in data flows. In BLPredict, we have implemented three of these methods, which are capable of adapting to changing behavior over time:
- The KDE method: based on the kernel density estimation approach. From a set of samples called kernel centers, a model is generated in the form of a function estimating the probability density associated with the data distribution. Thus, if a measurement lies in an area of the data space where the density is too low, it is considered abnormal. The main limitation of this approach is the choice of kernel centers among the measurements: their number must not depend on the size of the data stream. Their selection is therefore subjective, within a sliding window of fixed size to be defined.
- The DyCF method: based on the Christoffel function, borrowed from the theory of approximation and orthogonal polynomials. It models the sample set as a matrix of fixed size, depending only on the number of attributes and a method parameter. It defines an anomaly score that captures the support of the probability measure associated with the dataset. It is simpler to parameterize than the KDE method, but more difficult to interpret.
- The DyCG method: based on an asymptotic property of the Christoffel function. By setting two DyCF models with different parameters, it further reduces the number of parameters to be set. Although easier to parameterize than the DyCF method, it is also even more difficult to interpret.
By succinctly using these new methods with BLPredict, we’ll be able to carry out targeted detection, proposing new, more flexible thresholds on well-chosen attributes. Going a step further, we want to use our methods for systemic detection, taking all the attributes of a system as input and then automating the selection of key attributes. The aim here will be to identify abnormal and unexpected behavior at system level.
Deploying anomaly detection in BLPredict
In a system integrating a multitude of sensors, as is the case with BLPredict, model lifecycle management is crucial to maintaining good equipment performance, constant stability, and scalable adaptability of anomaly detection systems.
The MLOps approach is an essential element in coordinating the various phases of the model lifecycle. By adopting this approach, it becomes possible to implement simplified model management, from initial training through to deployment, updating and ongoing monitoring. Regular, automated training, update and inference cycles enable models to adjust dynamically to changes in data. This automation also facilitates monitoring, guaranteeing rapid detection of deviations in the data.
In BLPredict, we are experimenting with workflow orchestration systems and APIs for process automation, as well as machine learning model lifecycle management tools. We have carried out experiments on historical intensity and pressure data collected from air handling units.
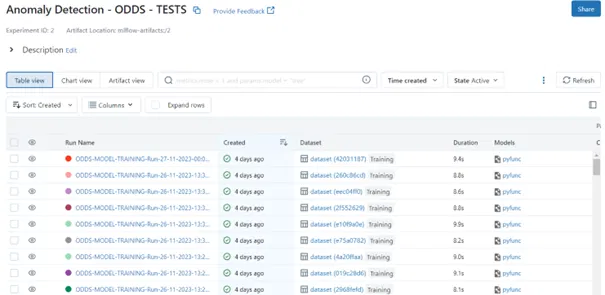
Eventually, we expect to be able to lift automatically defined alerts and discover new abnormal or unexpected behaviors.