La détection d’anomalies non supervisée permet d’automatiser des tâches relatives à la maintenance des équipements et infrastructures, jusqu’ici réalisées par des experts.
Parmi ses fonctionnalités, la plateforme de gestion des équipements BLPredict propose de définir manuellement des seuils d’alerte afin d’être averti lorsque les systèmes surveillés tombent en panne. Pour ce faire, chaque cas de pannes doit être référencé à l’aide de critères spécifiques traçables dans les mesures relevées par les capteurs.
Cependant, il est difficile de connaitre toute la liste des pannes possibles. Plus souvent, nous devons attendre de les observer (et donc d’en subir les conséquences) pour les formaliser… Ce qui peut s’avérer coûteux. Aussi, la détection d’anomalies non supervisée pourrait pallier ce problème en repérant automatiquement les comportements inattendus pour en informer directement l’opérateur.

Mais la détection d’anomalies, c’est quoi ?
La détection d’anomalies vise à mettre en évidence des comportements suspects ou des dégradations du fonctionnement à partir de l’analyse des données d’un système. Elle cherche à détecter des symptômes et se différencie ainsi du diagnostic qui permet d’en identifier les causes.
La détection d’anomalies est divisée en deux catégories :
- La détection supervisée réalise un apprentissage à partir de données labellisées, c’est-à-dire des mesures auxquelles sont associées l’étiquette « normal » ou « anormal ». Cette approche de détection génère un modèle qui sépare les mesures normales des mesures anormales. Parfois, elle peut même proposer un premier diagnostic.
- La détection non supervisée réalise un apprentissage à partir de données non labellisées, c’est-à-dire un ensemble de mesures dont on ne connait pas l’état. Cette méthode de détection crée un modèle qui formule des hypothèses pour établir des schémas de normalité au sein des données.
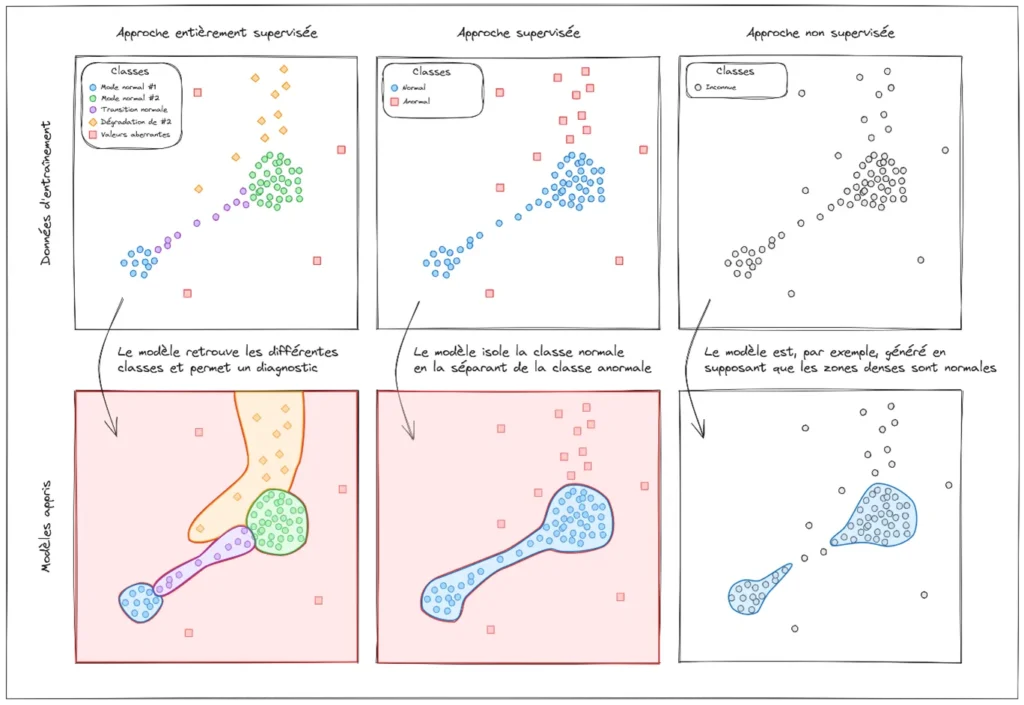
En pratique, les méthodes non supervisées caractérisent l’anormalité à travers un score d’anomalie ; plus leur score est élevé, plus les données analysées sont susceptibles de caractériser une potentielle défaillance.
Quelles spécificités dans BLPredict ?
Avec BLPredict, des capteurs sont positionnés sur des équipements dont on cherche à suivre et comprendre le fonctionnement. Ces capteurs relèvent des flux de données ; des mesures horodatées en temps réel. Ces mesures doivent donc être traitées au fil de l’eau, un comportement anormal nécessitant d’être détecté le plus tôt possible.
Les systèmes étudiés ont aussi la particularité d‘évoluer dans le temps, en suivant des modes de fonctionnement distincts ou en recevant une commande leur demandant de modifier leur comportement. Les modèles de détection d’anomalies doivent donc être en mesure de s’adapter à ces changements, ce qui n’est pas le cas des méthodes statiques, encore couramment utilisées.
Notre réponse avec BLPredict
Pour s’intégrer à BLPredict, les méthodes de détection d’anomalies doivent satisfaire les exigences suivantes :
- Pouvoir s’adapter rapidement aux nouvelles mesures,
- Être légères en mémoire (avec une indépendance au nombre de mesures), rapides d’exécution et aisément interprétables pour faciliter le diagnostic en aval de la détection,
- Être faciles à paramétrer pour réduire le degré de supervision humaine nécessaire à leur déploiement et à leur fonctionnement,
- Proposer des métriques de performances compréhensibles,
- Offrir la possibilité de combiner plusieurs modèles en un pour mutualiser les connaissances en cas de systèmes similaires.
Limites des approches actuelles
Les approches actuellement en place sont de deux formes :
- La définition d’alertes sur des seuils pour obtenir un suivi personnalisé du bon fonctionnement d’un système : elle peut rapidement manquer de flexibilité lorsque les seuils à fixer ne sont pas linéaires, dépendant d’un grand nombre d’attributs (multiplication des clauses) ou lorsqu’il existe un grand nombre de comportements anormaux (multiplication des règles).
- L’utilisation d’une méthode de détection d’anomalies statique appelée One-Class SVM pour s’assurer de la stabilité du comportement d’un système : statique par nature, elle ne permet pas de suivre l’évolution du comportement, pourtant nécessaire pour détecter tout changement et démarrer un nouvel apprentissage adapté aux nouveaux comportements des équipements à gérer.
Aspects techniques et bénéfices de notre solution
Afin d’optimiser la gestion des équipements et infrastructures, plusieurs méthodes peuvent être utilisées pour détecter des anomalies dans des flux de données. Nous implémentons plus particulièrement dans BLPredict trois d’entre elles capables de s’adapter à des comportements évoluant dans le temps :
- La méthode KDE : basée sur l’approche de l’estimation de densité par noyau. A partir d’un ensemble d’échantillons appelés centres de noyaux, un modèle est généré sous la forme d’une fonction estimant la densité de probabilité associée à la distribution des données. Ainsi, si une mesure se trouve dans une zone de l’espace des données où la densité est trop faible, elle est considérée anormale. La principale limite de cette approche est le choix des centres de noyaux parmi les mesures : leur nombre ne doit pas dépendre de la taille du flux de données. Ainsi, leur sélection s’effectue subjectivement dans une fenêtre glissante de taille fixe et à définir.
- La méthode DyCF : qui s’appuie sur la fonction de Christoffel, empruntée à la théorie de l’approximation et des polynômes orthogonaux. Elle modélise l’ensemble des échantillons sous la forme d’une matrice de taille fixe, qui ne dépend que du nombre d’attributs et d’un paramètre de la méthode. Elle définit un score d’anomalies qui capture le support de la mesure de probabilité associée au jeu de données. Elle est plus simple à paramétrer que la méthode KDE mais plus difficile à interpréter.
- La méthode DyCG : qui s’appuie sur une propriété asymptotique de la fonction de Christoffel. Elle permet, en fixant deux modèles de DyCF avec des paramètres différents, de réduire encore le nombre de paramètres à fixer. Bien que plus facile à paramétrer que la méthode DyCF, elle est également plus difficile encore à interpréter.
En utilisant succinctement ces nouvelles méthodes avec BLPredict, nous pourrons mener une détection ciblée, en proposant de nouveaux seuils, plus flexibles, sur des attributs bien choisis. Pour aller plus loin, nous souhaitons utiliser nos méthodes pour une détection systémique en prenant l’intégralité des attributs d’un système en entrée puis en automatisant la sélection d’attributs clés. L’objectif sera ici de déterminer des comportements anormaux et imprévus à l’échelle du système.
Le déploiement de la détection d’anomalies dans BLPredict
Dans un système intégrant une multitude de capteurs, comme c’est le cas de BLPredict, la gestion du cycle de vie des modèles est cruciale pour maintenir une bonne performance des équipements, une stabilité constante, et une adaptabilité évolutive des systèmes de détection d’anomalies.
L’approche MLOps est un élément essentiel pour coordonner les différentes phases du cycle de vie des modèles. En adoptant cette approche, il devient envisageable de mettre en œuvre une gestion simplifiée des modèles, depuis leur entraînement initial jusqu’à leur déploiement, mise à jour et leur surveillance continue. Les cycles d’entraînements, de mises à jour et d’inférences, automatisés et réguliers, permettent aux modèles de s’ajuster de manière dynamique aux évolutions des données. Cette automatisation facilite également la surveillance, garantissant une détection rapide des déviations dans les données.
Dans BLPredict, nous expérimentons des systèmes d’orchestration de workflows et des APIs pour l’automatisation des processus, ainsi que des outils de gestion de cycle de vie de modèles d’apprentissage automatique. Nous avons effectué des expérimentations sur des données historiques d’intensité et pression collectées à partir de centrales de traitement d’air.
A termes, nous pensons pouvoir lever des alertes définies automatiquement et découvrir de nouveaux comportements anormaux ou inattendus.